Real-time streaming transforms AI chatbots into natural conversational agents — enabling progressive, token-by-token responses that make interactions feel fluid, responsive, and human-like.
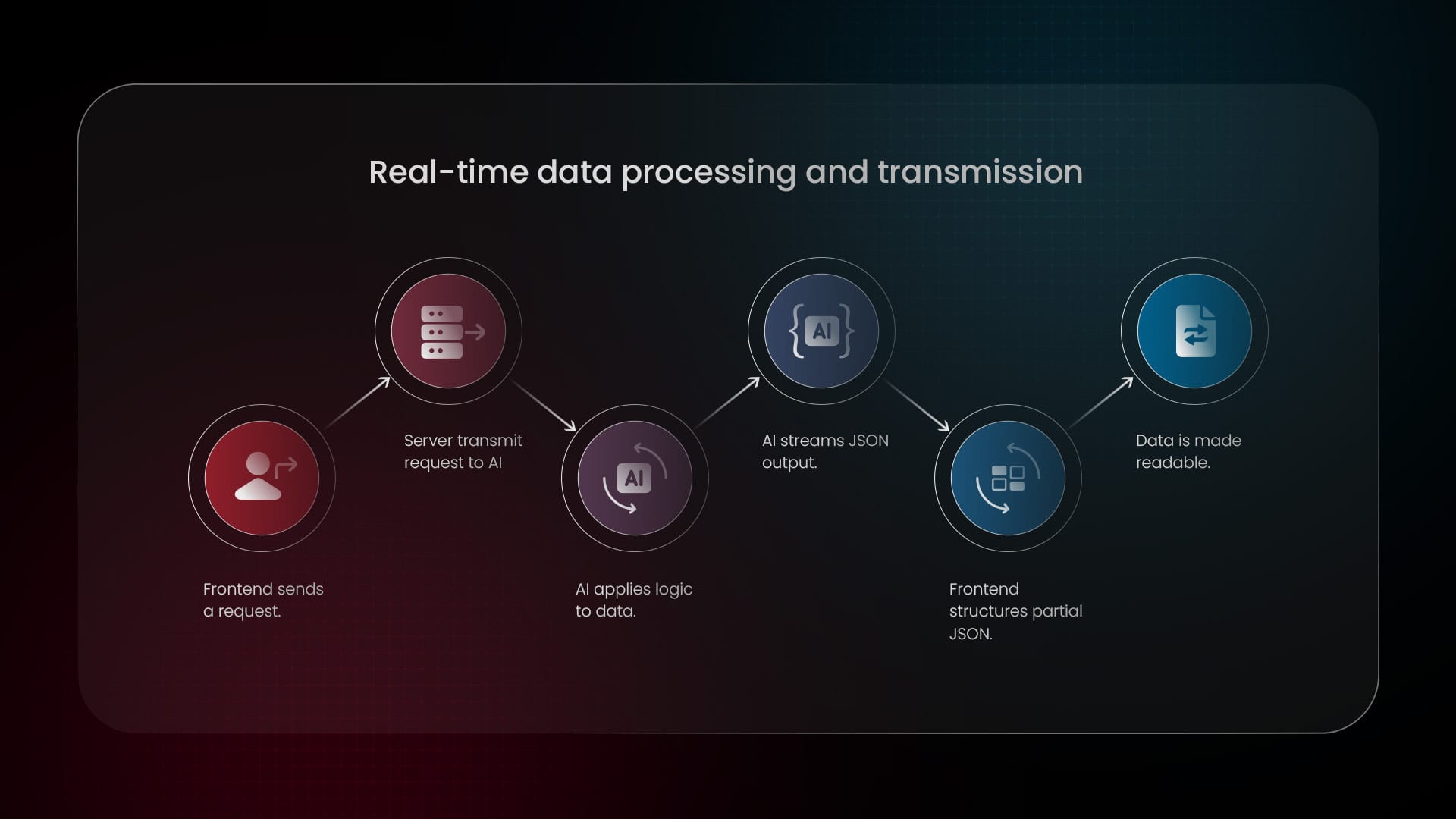
A robust streaming architecture combines Frontend, Server, and AI Model layers, ensuring seamless communication, lower latency, and dynamic UI updates without waiting for full responses.
Handling JSON streams intelligently is key to performance — implement partial JSON parsing and progressive rendering to manage fragmented data, boost perceived speed, and enhance user engagement.
In today's digital landscape, user expectations for AI chatbots have evolved dramatically. Gone are the days when users would patiently wait for a complete response to load. Modern AI applications need to feel alive, responsive, and natural - just like a conversation with a real person.
This is where real-time streaming techniques come into play, transforming the user experience from stilted and mechanical to fluid and engaging.
Read further to understand how an AI chatbot that uses real time streaming can be built from the perspective of both the client and server.
The challenge: Beyond static responses
Traditional chatbots follow a simple pattern: the user sends a message, waits for processing, and eventually receives a complete response. This approach creates noticeable delays and a disjointed experience that feels unnatural compared to human conversation.
Modern AI chat applications need to:
Display responses progressively as they're generated
Update the UI dynamically as new data becomes available
Present structured information (like cards or components) without waiting for complete data
The solution: Real-time streaming architecture
A well-designed streaming architecture consists of several key components working together seamlessly:
1. User Interface (Frontend)
The frontend is responsible for:
Rendering messages dynamically as they arrive
Maintaining a smooth, real-time experience by updating the UI progressively
Handling user input and sending messages to the backend
How streaming enhances the frontend:
Instead of waiting for complete responses, messages appear word-by-word or chunk-by-chunk, creating a natural conversation flow that keeps users engaged.
Technologies like React (useState, useEffect) and streams in Javascript help manage real-time updates efficiently
2. Server layer
The server acts as the bridge between the frontend and AI model, with responsibilities including:
Receiving user messages from the frontend
Forwarding requests to the AI model
Streaming responses back to the frontend in real-time
Handling security, rate-limiting, and authentication
3. AI model layer
This is where the Large Language Model (LLM) processes input and generates responses:
Receives processed input from the server
Generates text incrementally (token-by-token)
Sends partial responses back to the server for streaming
Streaming advantage: Instead of generating an entire response first, the model streams words progressively, significantly reducing perceived latency.
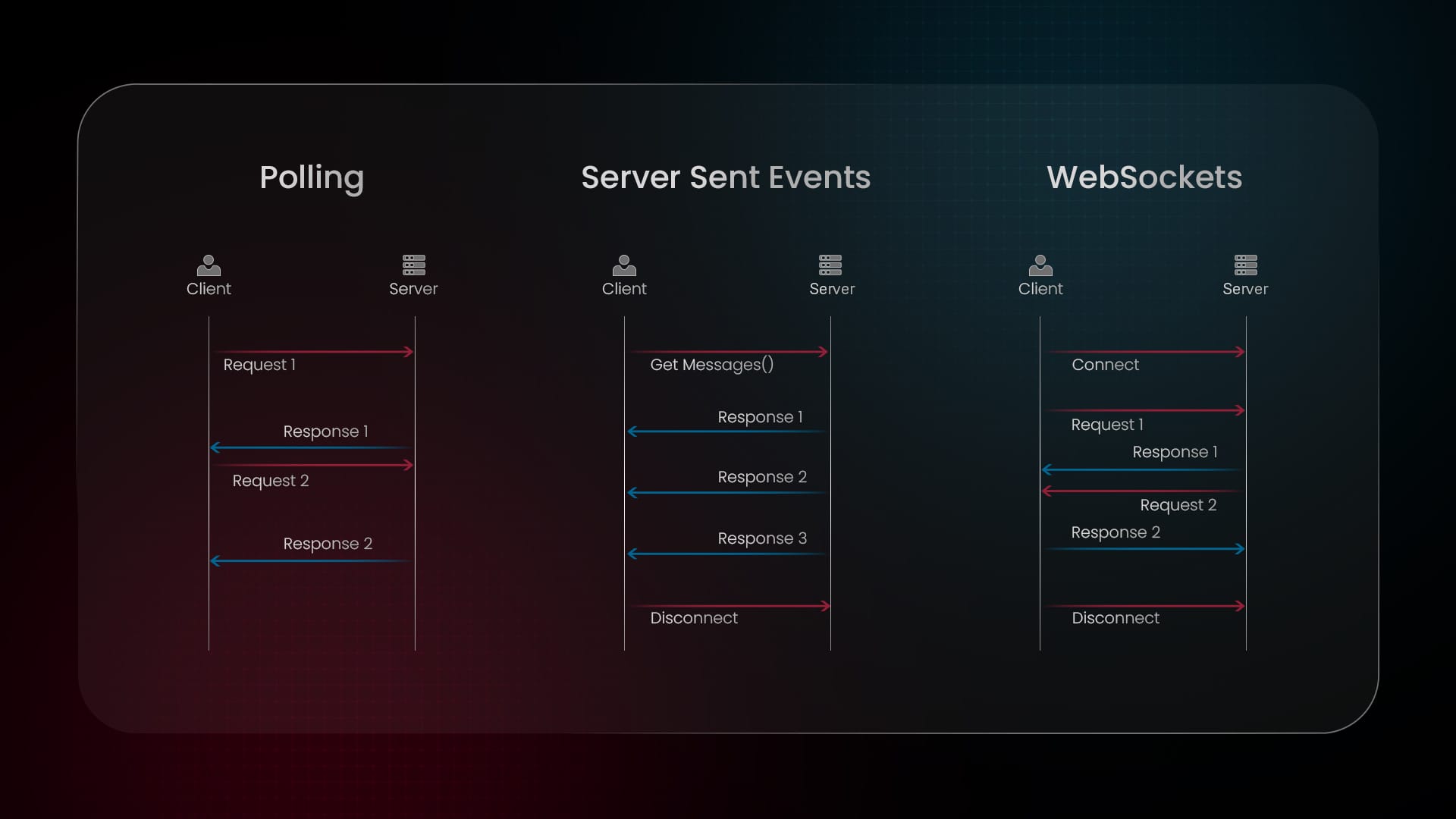
4. Stream layer (WebSockets or SSE)
This layer ensures real-time data transfer between the server and frontend:
Fast User Experience - Users see responses instantly
Efficient Data Handling - Avoid waiting for the full response
Supports custom headers and works with POST requests
Provides manual control over streamed data processing
The JSON streaming challenge in AI chatbots
Handling streaming responses is pretty straightforward when it involves only basic text format. However, it introduces unique challenges when handling structured data like JSON. For example, instead of returning a full JSON object after processing, the server can send pieces of JSON data as soon as they are available, reducing waiting time for the user.
Key challenges:
Incomplete JSON structure
AI-generated responses are streamed token by token
JSON requires complete structures with proper {} formatting
If a response is cut off mid-stream, parsing fails
Handling fragmented data
AI models generate text progressively
Each streamed chunk doesn't contain a fully formed JSON object
The frontend must buffer and reconstruct the JSON before parsing
Latency & ordering issues
Some chunks may arrive late or out of order
This can result in corrupted data if not handled correctly
Limited support in some APIs & browsers
Many HTTP-based APIs assume entire JSON objects are returned at once
Some browser APIs (like EventSource) only support text streaming, making it tricky to work with structured JSON
To solve these issues, Partial JSON Streaming is used. Instead of sending a single, large JSON object, responses are broken into smaller, self-contained JSON fragments that can be processed independently.
Solutions for handling partial JSON
When receiving partial JSON responses via SSE, the frontend must handle fragmented data and reconstruct it into valid JSON. Let us look at the various options available to streaming partial JSON.
1. Streaming JSON parsers
Libraries like partial-json help reconstruct fragmented JSON streams:
A more flexible approach is manually concatenating streamed data:
let jsonBuffer = '';
fetch('/stream-endpoint')
.then(response => response.body.getReader())
.then(reader => {
function processChunk({ done, value }) {
if (done) return;
jsonBuffer += new TextDecoder().decode(value);
try {
const parsedData = JSON.parse(jsonBuffer);
console.log('Complete JSON:', parsedData);
jsonBuffer = '';
} catch (e) {
// Incomplete JSON, wait for more data
}
reader.read().then(processChunk);
}
reader.read().then(processChunk);
});
This approach:
Fetches data from the /stream-endpoint using fetch() .
Reads streamed response using response.body.getReader() .
Appends chunks of data to jsonBuffer as they arrive.
Attempts to parse JSON using JSON.parse(jsonBuffer) .
If parsing fails, it waits for more data instead of throwing an error.
Once a valid JSON object is formed, it logs the output and resets jsonBuffer
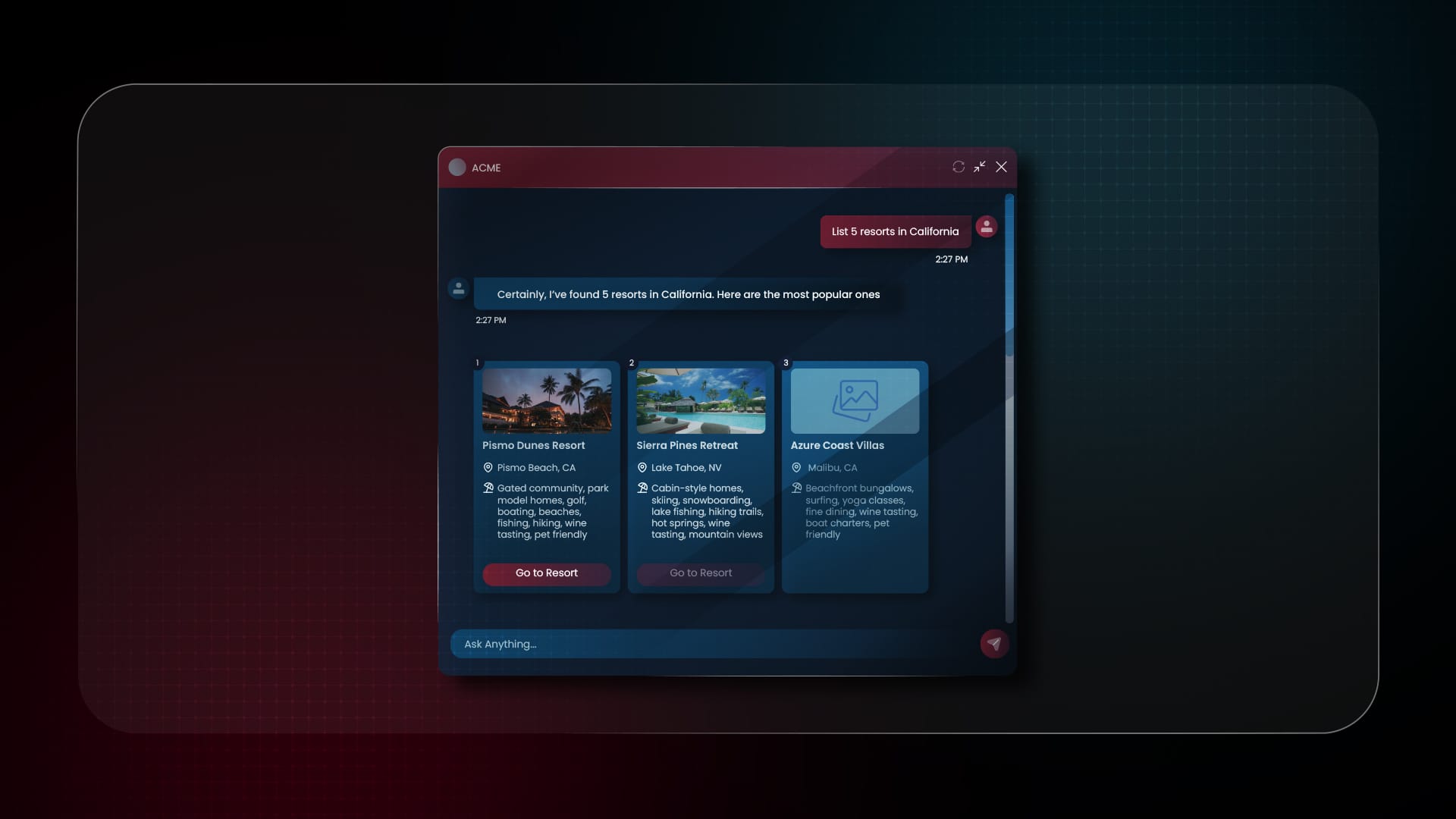
Real-world example: An AI travel assistant
Imagine a travel assistant chatbot that recommends resorts. With streaming:
The initial response begins appearing immediately, word by word
As the AI generates resort recommendations, cards begin to appear with basic info
Images and additional details load progressively as they become available
Users can start interacting with the first recommendations while others are still loading
This progressive loading creates a significantly more responsive experience than waiting for all data to be generated and rendered at once.
Key takeaways for developers
Choose the right transmission method: SSE for one-way updates, WebSockets for bidirectional communication
Implement proper streaming techniques: Use EventSource API for simple cases or Fetch with ReadableStream for more flexibility
Handle JSON streams carefully: Implement robust parsing of fragmented JSON to ensure data integrity
Design for progressive rendering: Show incomplete components first, allowing users to engage sooner
Optimize the entire pipeline: From AI model to frontend rendering, every component should support streaming
By implementing these techniques, you can build AI applications that feel significantly faster and more engaging, even when complex processing is happening behind the scenes.
The future of AI interfaces lies in creating experiences that feel as natural and responsive as human conversation – and real-time streaming is the key to making that possible.
KeyValue is redefining how users interact with AI, making every conversation fluid, instant, and intelligent.
Partner with us to engineer AI experiences that feel truly human.
FAQs
What is an AI chatbot?
An AI chatbot is an application that uses large language models (LLMs) to understand user input and generate context-aware, human-like responses in real time. Unlike traditional scripted bots, it processes natural language dynamically — interpreting intent, managing dialogue flow, and streaming responses token-by-token to create a smooth, conversational experience.
What is streaming in chatbots?
Streaming in chatbots is the process of delivering AI-generated responses incrementally, token by token, as they’re produced by the model. Instead of waiting for the full reply, the chatbot streams partial outputs in real time, making conversations faster, smoother, and more human-like.
Why is real-time streaming important for chatbots?
Real-time streaming minimizes response delays, allowing messages to appear as they’re generated. This creates a smoother, more conversational experience that feels closer to real human interaction.
How does the streaming architecture work?
The frontend sends user input to the server, which forwards it to the AI model. The model streams its response back to the server, which relays chunks to the frontend via WebSockets or SSE for real-time display.
What are WebSockets?
WebSockets are a communication protocol that enables full-duplex, real-time data exchange between a client and server over a single persistent connection. Unlike HTTP, which requires repeated requests, WebSockets keep the connection open—allowing both sides to send and receive messages instantly, making them ideal for interactive chat systems and live AI applications.
When should I use SSE vs WebSockets?
Use SSE for one-way data flow like AI-generated responses, as it’s lightweight and easy to implement. Use WebSockets when two-way communication is needed, such as in multi-user chat systems.
What are the challenges with JSON streaming?
AI models stream output token-by-token, which can fragment JSON data. Developers must handle incomplete structures, reorder delayed chunks, and reconstruct valid JSON before parsing.